Andrew Ng机器学习课程笔记(第四周至第七周)
本笔记基于Coursera上吴恩达(Andrew Ng)的机器学习课程内容集结而成。(课程链接)
全课程分为十一周,每周都有1-3个测验。第二周至第九周附有编程作业,一共8份。
第四周
神经网络
如果假设函数十分复杂,单纯的回归公式将会包含数量庞大的参数。使用神经网络是一个好的解决方法。
逻辑激励函数(sigmoid (logistic) activation function):
\[\frac{1}{1 + e^{-\theta^Tx}}\]
\(a_i^{(j)}\)代表的是第\(j\)层中,\(i\)单位的激励。\(\theta^{(j)} \)代表的是矩阵中控制从第\(j\)层到第\(j+1\)层的投影的比重。
如果神经网络只有一层隐含层,看起来就像这样:
\[\begin{bmatrix}x_0 \newline x_1 \newline x_2 \newline x_3\end{bmatrix}\rightarrow\begin{bmatrix}a_1^{(2)} \newline a_2^{(2)} \newline a_3^{(2)} \newline \end{bmatrix}\rightarrow h_\theta(x) \]
而其中,每个激励节点的数值都是根据公式算出来的:
\[
\begin{align*}
a_1^{(2)} = g(\Theta_{10}^{(1)}x_0 + \Theta_{11}^{(1)}x_1 + \Theta_{12}^{(1)}x_2 + \Theta_{13}^{(1)}x_3) \newline
a_2^{(2)} = g(\Theta_{20}^{(1)}x_0 + \Theta_{21}^{(1)}x_1 + \Theta_{22}^{(1)}x_2 + \Theta_{23}^{(1)}x_3) \newline
a_3^{(2)} = g(\Theta_{30}^{(1)}x_0 + \Theta_{31}^{(1)}x_1 + \Theta_{32}^{(1)}x_2 + \Theta_{33}^{(1)}x_3) \newline
h_\Theta(x) = a_1^{(3)} = g(\Theta_{10}^{(2)}a_0^{(2)} + \Theta_{11}^{(2)}a_1^{(2)} + \Theta_{12}^{(2)}a_2^{(2)} + \Theta_{13}^{(2)}a_3^{(2)}) \newline
\end{align*}
\]
至于每一层的\(\theta^{(j)}\),该矩阵的维度是根据该层和下一层的度数决定的。也就是:
如果一个神经网络的第\(j\)层中有\(s_j\)个单位/节点,第\(j+1\)有\(s_{j+1}\)个单位/节点,参数矩阵\(\theta^{(j)}\)的维度则是\(s_{j+1} \times (s_j + 1) \)。额外+1来自于偏差节点,每一层都要新加一个偏差节点来计算。
引用\(z_k^{(j)}\),
\[
\begin{align*}a_1^{(2)} = g(z_1^{(2)}) \newline a_2^{(2)} = g(z_2^{(2)}) \newline a_3^{(2)} = g(z_3^{(2)}) \newline \end{align*}
\]
换句话说,
\[z_k^{(2)} = \Theta_{k,0}^{(1)}x_0 + \Theta_{k,1}^{(1)}x_1 + \cdots + \Theta_{k,n}^{(1)}x_n\]
用矩阵表示:
\[\begin{align*}x = \begin{bmatrix}x_0 \newline x_1 \newline\cdots \newline x_n\end{bmatrix} &z^{(j)} = \begin{bmatrix}z_1^{(j)} \newline z_2^{(j)} \newline\cdots \newline z_n^{(j)}\end{bmatrix}\end{align*}\]
设置\(x = a^{(1)}\),
\[z^{(j)} = \Theta^{(j-1)}a^{(j-1)}\]
\[h_\Theta(x) = a^{(j+1)} = g(z^{(j+1)})\]
多元分类
神经网络算出来的向量可能是这样:
\[h_\Theta(x) =\begin{bmatrix}0 \newline 0 \newline 1 \newline 0 \newline\end{bmatrix}\]
这时候,结果可以分为这样
\[y^{(i)} =\begin{bmatrix}0 \newline 0 \newline 1 \newline 0 \newline\end{bmatrix},\begin{bmatrix}1 \newline 0 \newline 0 \newline 0 \newline\end{bmatrix},\begin{bmatrix}0 \newline 1 \newline 0 \newline 0 \newline\end{bmatrix}, \begin{bmatrix}0 \newline 0 \newline 0 \newline 1 \newline\end{bmatrix}\]
第五周
神经网络的代价函数
定义L为神经网络总共的层数,\(s_l\)为第l层中的节点数,K为输出的节点数。
神经网络的代价函数为:
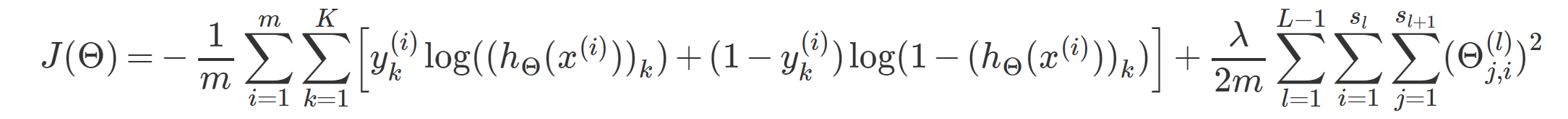
反向传播算法
反向传播算法的目标是计算出\(min_\theta J(\Theta) \),而就是在什么情况下,代价函数的数值最小。同样,先找出代价函数的偏积分,假设\(\delta_j^{(l)}\)为第l层中节点j的误差。
在最后一层中,可以得知\(\delta^{(L)} = a^{(L)} - y\),L是神经网络中的总层数,\(a^{(L)}\)是激励节点的输出向量。最后该公式只是算出神经网络的结果与实际数值的误差。
每一个节点的误差可以用这个公式来表示:
\[\delta^{(l)} = ((\Theta^{(l)})^T \delta^{(l+1)})\ .*\ g'(z^{(l)})\]
代价函数的偏积分(无视正规化):
\[\dfrac{\partial J(\Theta)}{\partial \Theta_{i,j}^{(l)}} = \frac{1}{m}\sum_{t=1}^m a_j^{(t)(l)} {\delta}_i^{(t)(l+1)}\]
流程:
- 设置\(\Delta^{(l)}_{i,j} := 0\)
- 从t = 1 到 t = m循环:
a. 设置\(a^{(1)} := x^{(t)}\)
b. 计算\(a^{(l)}\)
c. 用\(y^{(t)}\)计算\(\delta^{(L)} = a^{(L)} - y\)
d. 利用公式\(\delta^{(l)} = ((\Theta^{(l)})^T \delta^{(l+1)})\ .* a^{(l)}\ .* (1 - a^{(l)})\),计算\(\delta^{(L)}\)
e. \(\Delta^{(l)} := \Delta^{(l)} + a_j^{(l)} \delta_i^{(l+1)}\)或者使用矩阵\(\Delta^{(l)} := \Delta^{(l)} + \delta^{(l+1)}(a^{(l)})^T\)
f. \(D^{(l)} := \frac{1}{m} (\Delta^{(l)})\)
g. \(D^{(l)} := \dfrac{1}{m}\Delta^{(l)}\)
反向传播的代价函数
\[
\begin{gather*}J(\theta) = - \frac{1}{m} \sum_{t=1}^m \sum_{k=1}^K \left[ y^{(t)} \ \log (h_\theta (x^{(t)})) + (1 - y^{(t)})\ \log (1 - h_\theta(x^{(t)}))\right] +
\frac{\lambda}{2m}\sum_{l=1}^{L-1} \sum_{i=1}^{s_l} \sum_{j=1}^{s_l+1} ( \theta_{j,i}^{(l)})^2
\end{gather*}
\]
如果只是单一分类和务实正规化,代价函数可以写成:
\[cost(t) =y^{(t)} \ \log (h_\theta (x^{(t)})) + (1 - y^{(t)})\ \log (1 - h_\theta(x^{(t)}))\]
梯度检查
\[
\dfrac{\partial}{\partial\Theta_j}J(\Theta) \approx \dfrac{J(\Theta_1, \dots, \Theta_j + \epsilon, \dots, \Theta_n) - J(\Theta_1, \dots, \Theta_j - \epsilon, \dots, \Theta_n)}{2\epsilon}
\]
随机初始
模型设置时,\(\Theta\)不能初始为0,需要随机选择一个非零正数。应该设置\(\Theta^{(l)}_{ij}\)的范围为\([-\epsilon,\epsilon]\)。公式为:
\[\begin{gather}
\epsilon = \dfrac{\sqrt{6}}{\sqrt{\mathrm{Loutput} + \mathrm{Linput}}} \cr
\Theta^{(l)} = 2 \epsilon ; \mathrm{rand}(\mathrm{Loutput}, \mathrm{Linput} + 1) - \epsilon
\end{gather}\]
组合起来
- 随机选择初始\(\Theta\)的比重。
- 用正向传播计算出\(h_{\theta}^{(i)}\)。
- 设置代价函数。
- 用反向传播算出偏积分。
- 用梯度检查的方法确认反向传播无误。
- 用梯度下降逐步减少误差和修改\(\Theta\)的比重。
第六周
预测误差可以用以下几种方法修正:
- 取得更多训练样本
- 使用更小的特征集
- 使用更多的特征
- 使用多元组合特征
- 增加或减少\(\lambda\)
评估假设
将训练样本分类两个组/集,一个是训练组,一个是测试组。
先用训练组来训练模型,然后计算出测试组的误差。
测试误差
线性回归:
\[J_{test}(\Theta) = \dfrac{1}{2m_{test}} \sum_{i=1}^{m_{test}}(h_\Theta(x^{(i)}) - y^{(i)})^2\]
逻辑回归:
\[err(h_\Theta(x),y) =
\begin{matrix}
1 & \mbox{if } h_\Theta(x) \geq 0.5\ and\ y = 0\ or\ h_\Theta(x) < 0.5\ and\ y = 1\newline
0 & \mbox otherwise
\end{matrix}\]
平均测试误差:
\[\text{Test Error} = \dfrac{1}{m_{test}} \sum_{i=1}^{m_{test}} err(h_\Theta(x^{(i)}), y^{(i)})\]
模型选择和训练\验证\测试组
没有验证组(不好的方法,不推荐):
- 使用训练组和不同多项式次数(polynomial degree)的来训练模型。
- 用模型组来测试,选择最佳的多项式次数。
- 用\(J_{test}(\Theta^{(d)})\)找出最后的误差。
使用验证组:
在使用验证组的情况下,数据应分为3组,60%归入训练组,20%归入验证组,20%归入测试组。
- 用训练组训练模型。
- 使用验证组选择最佳的多项式次数。
- 用\(J_{test}(\Theta^{(d)})\)算出最后的误差。
诊断偏差和方差问题
高偏差是欠拟合问题,高方差是过拟合问题。如果选择高多项式次数,测试误差会减少。同时,验证误差会减少到一定程度,然后又上升。
高偏差(欠拟合):\(J_{train}(\Theta)\)和\(J_{CV}(\Theta)\)都很大。同时\(J_{CV}(\Theta) \approx J_{train}(\Theta)\)。
高方差(过拟合):\(J_{train}(\Theta)\)很低,但\(J_{CV}(\Theta)\)会远远高于\(J_{train}(\Theta)\)。
正规化和偏差/方差
正规化参数\(\lambda\)也会造成偏差和方差问题。
\(\lambda\)过大:高偏差(欠拟合),\(J_{train}(\Theta)\)和\(J_{CV}(\Theta)\)都很大。
\(\lambda\)适中:正好,\(J_{CV}(\Theta)\)和\( J_{train}(\Theta)\)都差不多。\(J_{CV}(\Theta) \approx J_{train}(\Theta)\)
\(\lambda\)过小:过方差(过拟合),\(J_{train}(\Theta)\)很低,\(J_{CV}(\Theta)\)很大。
为了选择一个最合适的\(\lambda\)数值,选择做一下步骤:
- 创建一个\(\lambda\)列表(从0,0.01,0.01,0.02,0.04...)
- 使用各种多项式次数来创建模型。
- 使用不同\(\lambda\)来训练模型。
- 计算出不同模型,不同\(\lambda\)下的验证组误差。
- 选择最低的误差组合。
- 用测试组来该组合的误差。
学习曲线
高偏差:
小训练组会造成低/小\(J_{train}(\Theta)\)和高/大\(J_{CV}(\Theta)\)。
大训练组会造成\(J_{train}(\Theta)\)和\(J_{CV}(\Theta)\)都很大,同时\(J_{train}(\Theta) \approx J_{CV}(\Theta)\)。
为高偏差模型提供更多的训练数据更不能有所帮助。
高方差:
小训练组会造成低/小\(J_{train}(\Theta)\)和高/大\(J_{CV}(\Theta)\)。
大训练组会造成\(J_{train}(\Theta)\)上升,\(J_{CV}(\Theta)\)会持续下降。\(J_{train}(\Theta) < J_{CV}(\Theta)\)然后误差依旧明显存在。
为高方差模型提供更多的训练数据可以解决问题。
神经网络:
小型神经网络(小特征)易于产生高偏差问题,同时计算成本很低。
大型神经网络(多特征)易于产生高方差问题,同时计算成本很高。
机器学习系统设计
偏态类别(skewed classes)的错误分析
如果使用数据组不能涵盖所有/整体的数据组别,偏态类别的情况会发生。也就是说有一个类别的数据远远多于其他类别的数据。
精确率和召回率(Precision and Recall)
预测:1, 实际:1 —— 真正(True Positive)
预测:0, 实际:0 —— 真负(True Negative)
预测:0, 实际:1 —— 假负(False Negative)
预测:1, 实际:0 —— 假正(False Positive)
精确率:
\[\dfrac{\text{True Positives}}{\text{Total number of predicted positives}}
= \dfrac{\text{True Positives}}{\text{True Positives}+\text{False positives}}\]
召回率:
\[\dfrac{\text{True Positives}}{\text{Total number of actual positives}}= \dfrac{\text{True Positives}}{\text{True Positives}+\text{False negatives}}\]
准确率:
\[\frac {true positive + true negative} {total population}\]
精确率和召回率的权衡
提高判断的阀限可以提高精确率,但是会降低召回率。模型的预测确信度提高。
降低判断的阀限可以提高召回率,但是会降低精确率。模型的预测安全性提高。
F数值(也叫F1数值)是用于计算一个模型的精确率和召回率的指标。
\[\text{F Score} = 2\dfrac{PR}{P + R}\]
在验证组上算出F数值可以避免在测试组上出现精确率和召回率的问题。
一个模型需要采取足够的特征才能有足够的信息去判断。常用的方法:如果给予输入X,一个人类专家能否自信地判断出y?
大数据的原则:如果模型的偏差很低,给予越多的数据就越能减少过拟合的问题。
第七周
支持向量机(Support Vector Machine)(SVM)
先设置z:
\[\begin{gather}
z = \theta^Tx \cr
\text{cost0} (z) = \max(0, k(1+z)) \cr
\text{cost1} (z) = \max(0, k(1-z))
\end{gather}
\]
代价函数:
\[J(\theta) = C\sum_{i=1}^m y^{(i)} \ \text{cost1}(\theta^Tx^{(i)}) + (1 - y^{(i)}) \ \text{cost0}(\theta^Tx^{(i)}) + \dfrac{1}{2}\sum_{j=1}^n \Theta^2_j\]
其中\(C = \frac{1}{\lambda}\)。这条公式已经是优化的版本。
假设函数:
\[h_\theta(x) =\begin{cases} 1 & \text{if} \ \Theta^Tx \geq 0 \ 0 & \text{otherwise}\end{cases}\]
大边界分类
如果C的数值极大,代价函数的公式则是:
\[\begin{align*}
J(\theta) = C \cdot 0 + \dfrac{1}{2}\sum_{j=1}^n \Theta^2_j \newline
= \dfrac{1}{2}\sum_{j=1}^n \Theta^2_j
\end{align*}\]
核函数(Kernels)
使用该方法的SVM能制造非线性分类方法。
先使用多个坐标\(l^{(1)},\ l^{(2)},\ l^{(3)}\),计算出新特征和特征之间的邻近值。
\[f_i = similarity(x, l^{(i)}) = \exp(-\dfrac{||x - l^{(i)}||^2}{2\sigma^2})\]
使用高斯核函数,相似度公式则改成:
\[f_i = similarity(x, l^{(i)}) = \exp(-\dfrac{\sum^n_{j=1}(x_j-l_j^{(i)})^2}{2\sigma^2})\]
假设函数就变成:
\[
\begin{align*}l^{(1)} \rightarrow f_1 \newline l^{(2)} \rightarrow f_2 \newline l^{(3)} \rightarrow f_3 \newline\dots \newline h_\Theta(x) = \Theta_1f_1 + \Theta_2f_2 + \Theta_3f_3 + \dots\end{align*}
\]
核函数(Kernels II)
可以把坐标设置在训练数据上,然后每一个训练数据都有一个坐标。\(f_1 = similarity(x,l^{(1)}) ...\)
\[
x^{(i)} \rightarrow \begin{bmatrix}f_1^{(i)} = similarity(x^{(i)}, l^{(1)}) \newline f_2^{(i)} = similarity(x^{(i)}, l^{(2)}) \newline\vdots \newline f_m^{(i)} = similarity(x^{(i)}, l^{(m)}) \newline\end{bmatrix}
\]
用\(f^{(i)}\)来取代\(x^{(i)}\):
\[\min_{\Theta} C \sum_{i=1}^m y^{(i)}\text{cost1}(\Theta^Tf^{(i)}) + (1 - y^{(i)})\text{cost0}(\theta^Tf^{(i)}) + \dfrac{1}{2}\sum_{j=1}^n \Theta^2_j\]
如果C太大,会造成高方差,低偏差。
如果C太小,会造成高偏差,低方差。
要多元分类的话,参考逻辑回归中的方法(one vs all)。
如果n的数值很大(相对于m),选择逻辑回归或者不包含核函数的SVM。
如果n的数值很小(m的数值中等),选择包含高斯核函数的SVM。
如果n的数值很小(m的数值很大),人为增加特征的数量,用逻辑回归或者不包含核函数的SVM。